
Imagine chatting with a website to extract information, similar to conversing with a human. This is where LangChain comes into play. LangChain is a powerful tool for natural language processing (NLP), enabling AI-based conversational interfaces. In this article, we’ll explore how to use LangChain to create a chat interface that interacts with content extracted from a website.
What is Langchain?
LangChain is an open-source framework designed to enhance the capabilities of large language models (LLMs) like GPT-4 by integrating them with external sources of computation and data. It provides developers with tools to connect LLMs to personal or proprietary data sources, such as databases, documents, and APIs, thereby enabling more customized and data-aware applications.
LangChain’s ability to connect LLMs to personal data, execute actions, and integrate with APIs opens up possibilities for various applications, including personal assistants, data analytics, and learning tools. This framework is particularly beneficial for developing applications that require access to specific data sets or need to perform actions based on the model’s outputs.
Before getting started, Let’s understand how this questing answering works.
How the System Works
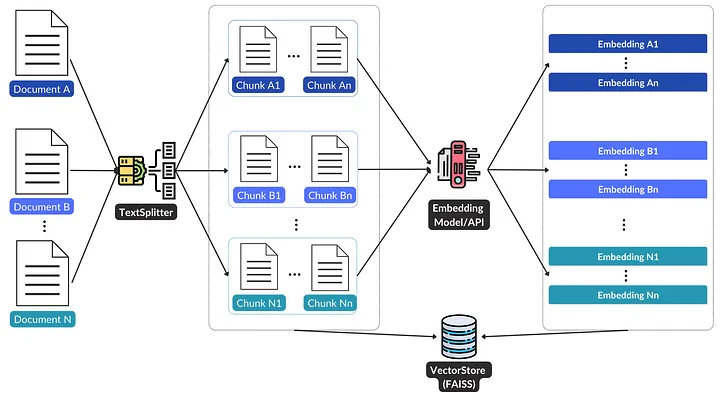
Source: TowardsDataScience
- We will first fetch the data(text) from the URLs (using langchain.document_loaders‘s UnstructuredURLLoader).
- Next, We will convert the text to embeddings, smaller, dense vectors that capture the essence of the text in numerical form (using HuggingFaceHubEmbeddings from langchain.embeddings)
- Now We will store all the embeddings in a vector store which will make it easier to retrieve the information. Here we are using Faiss(Facebook AI Similarity Search) for storing which helps to quickly search for embeddings of documents that are similar to each other. The vector store is the knowledge base of the chatbot.
- The next step is to do the Information Retrieval. For this, we will retrieve the information from the vector store ( Using RetrievalQAWithSourcesChain from langchain.chains).
- But we will need the response in natural language to understand. For this, we need to use LLMs. ( Using HuggingFaceHub from Langchain).
- The next step is to query. Here’s Query Processing Workflow:
- Receiving User Queries: The chatbot receives a query from the user.
- Converting Query to Embedding: The query is converted into an embedding.
- Searching the Vector Store: The embedding of the query is compared against the stored embeddings to find the most relevant information.
- Context Retrieval: Retrieve the original text chunks corresponding to the closest embeddings.
- Generating a Response: Feed the retrieved context and the user query into the LLM to generate a coherent and contextually relevant response.
Now Let’s get started.
Setting Up the Environment
Firstly, we need to set up our Python environment. Install the necessary packages using pip:
!pip install langchain
!pip install unstructuredLangChain facilitates advanced NLP tasks and unstructured aids in managing unstructured data like articles, social media posts, etc.
Extracting Web Content
We begin by defining URLs from which to scrape content. For this, I am using the Kickerai site. You can use any website you like (needs permission). Please don’t use my site because it might go down.
urls = ["https://example.com/article1", "https://example.com/article2"]
Next, import UnstructuredURLLoader from LangChain and load the data:
from langchain.document_loaders import UnstructuredURLLoader
loaders = UnstructuredURLLoader(urls=urls)
data = loaders.load()This step involves scraping content from the specified URLs.

Processing the Data
Once the data is loaded, we need to manage its size for efficient processing. We use CharacterTextSplitter to split the text into smaller chunks:
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(separator="\n", chunk_size=1000, chunk_overlap=200)
docs = text_splitter.split_documents(data)This process makes the large text data more manageable and ready for interaction.
Splitting the text into smaller, manageable chunks is a strategic approach to make the information processing by language models more effective, efficient, and contextually accurate. It’s a way to adapt the data to fit the operational constraints and capabilities of the models being used.
An overlap in the chunks is to ensure continuity and context. If a concept or sentence is split between two chunks without overlap, it might lose its meaning or context. Overlapping ensures that important information is not missed or misunderstood due to being cut off mid-context.
Note: If the chunks are not being split into a defined chunk_size, then you can use RecursiveCharacterTextSplitter.
text_splitter = RecursiveCharacterTextSplitter(separators=[" ", ",", "\n"],
chunk_size = 1000,
chunk_overlap = 100
)We will use text_splitter.split_documents to split the data into chunk sizes of 1000 tokens.
docs = text_splitter.split_documents(data)
Converting Documents into Embeddings
In this step, we will convert the text in the documents into Embeddings. Embeddings are smaller, dense vectors that capture the essence of the text in numerical form.
We will be using HuggingFaceHubEmbeddings from langchain.embeddings.
For this, you will need a HuggingFace API/Access Key. Do note that there are many ways to create embeddings. For example, you may use OpenAI’s embeddings text-embedding-ada-002 model for this process. This is much better than Huggingface but since it requires money, I am using the free option.
from langchain.embeddings import HuggingFaceHubEmbeddings
embeddings = HuggingFaceHubEmbeddings(huggingfacehub_api_token='xxxx')Storing the Embeddings into Vector Store
!pip install faiss-cpuFaiss(Facebook AI Similarity Search) is a library for efficient similarity search and clustering of dense vectors. It was developed by Facebook’s AI Research team. Faiss is used for tasks that involve large-scale vector similarity search, like finding similar items in a database of vectors, or for clustering large sets of vectors.
It is particularly useful in the context of machine learning and natural language processing for tasks like document retrieval, where embeddings (dense vector representations of text or other data) need to be compared and searched efficiently. The library is optimized for memory usage and speed, making it suitable for handling very large datasets.
There are other efficient libraries for storing available like chromadb.
import faiss
from langchain.vectorstores import FAISS
vectorStore = FAISS.from_documents(docs,embeddings)Setting Up LLM
We have our knowledge base ready. Now Let’s set up an LLM for question and answering.
from langchain.chains.question_answering import load_qa_chain
from langchain import HuggingFaceHub
load_qa_chain: A function to load a pre-configured QA chain.HuggingFaceHub: A class to interact with models hosted on Hugging Face’s Model Hub.
llm = HuggingFaceHub(repo_id='google/flan-t5-base', huggingfacehub_api_token='xx', model_kwargs={"temperature":0.9, "max_length":512})repo_id='google/flan-t5-base': Specifies the repository ID of the model on Hugging Face’s Model Hub. Here, it’s using Google’s FLAN-T5 base model, a variant of the T5 model trained for few-shot learning.huggingfacehub_api_token='xx': An API token for authentication with Hugging Face’s Model Hub. The ‘xx’ is a placeholder and should be replaced with a valid token.model_kwargs: A dictionary of keyword arguments for the model. In this case, it sets thetemperaturefor generating responses (a measure of randomness) and themax_lengthof the generated response.
Note: You can use Open AI models like GPT 3, and 3.5 here which will perform way better than the free ones I am using above.
Retrieving Information from Vector Store
from langchain.chains import RetrievalQAWithSourcesChain
chain = RetrievalQAWithSourcesChain.from_llm(llm=llm, retriever=vectorStore.as_retriever())
RetrievalQAWithSourcesChain: A class that facilitates question-answering (QA) tasks by retrieving relevant information from various sources.
The second line of code creates an instance of RetrievalQAWithSourcesChain using the large language model initialized earlier.
The retriever parameter is set to vectorStore.as_retriever(). This implies that there’s a vectorStore object that is being used as a retriever. This would be the component that helps in retrieving relevant information or documents based on vector similarity, which is essential for the QA task.
Now we will retrieve the information using a chain object in this format.
chain({'question':'What Flutter Courses Should I read?'}, return_only_outputs=True)and I got this output
{'answer': 'The Complete 2021 Flutter Development Bootcamp with Dart by Dr. Angela Yu',
'sources': ''}I played around for a while with this and got basic answers.

Some questions were answered and some weren’t. But it is expected since I am using a free open source model.
Conclusion
The answers were fine. I think if I tried using OpenAI embeddings and LLM models, I could have gotten better answers. However, since my card is not working with them, I was unable to buy the credits. Also, my free credits expired. I will update the article when I am able to buy the credits.
Integrating chat functionalities with website content using LangChain opens up new possibilities for user interaction. This technology can significantly enhance user experience, making information retrieval more interactive and engaging.